In this paper, we learn visual representations that convey camera properties by creating a joint embedding between image patches and photo metadata. This model treats metadata as a language-like modality: it converts EXIF tags that compose the metadata into a long piece of text,
and processes it using an off-the-shelf model from natural language processing. We demonstrate the effectiveness of our learned features on a variety of downstream tasks that require an understanding of low-level imaging properties, where it outperforms other feature representations.
In particular, we successfully apply our model to the problem of detecting image splices "zero shot", by clustering the crossmodal embeddings within an image.
Cross-modal Training
Photo metadata for each image (EXIF file) is a freely available but often ignored signal that can be used to learn camera property from images. We propose to treat EXIF tags as language and use multimodal contrative learning techniques to associate images with their metadata.
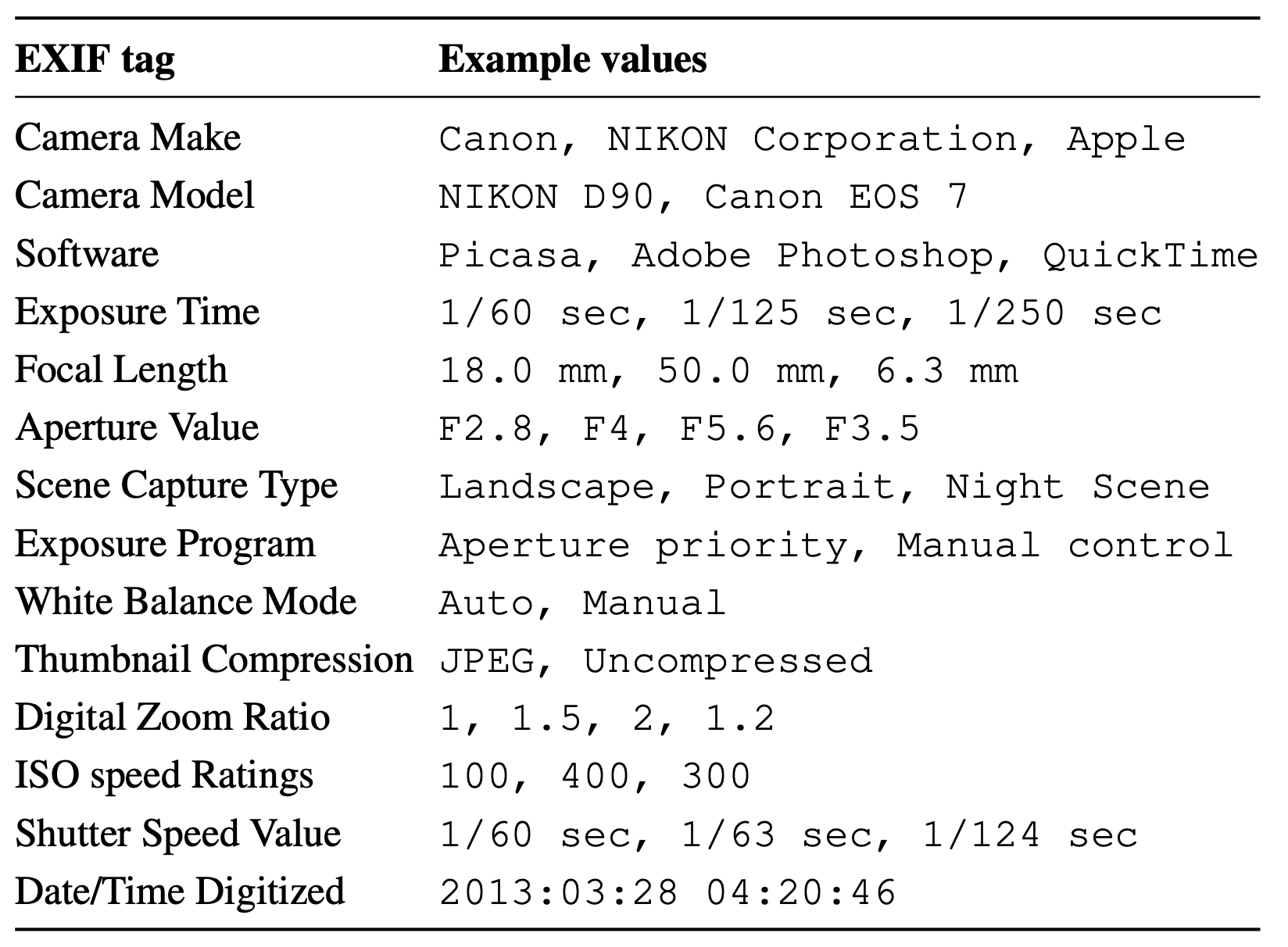 Common EXIF tags and example values
Common EXIF tags and example values
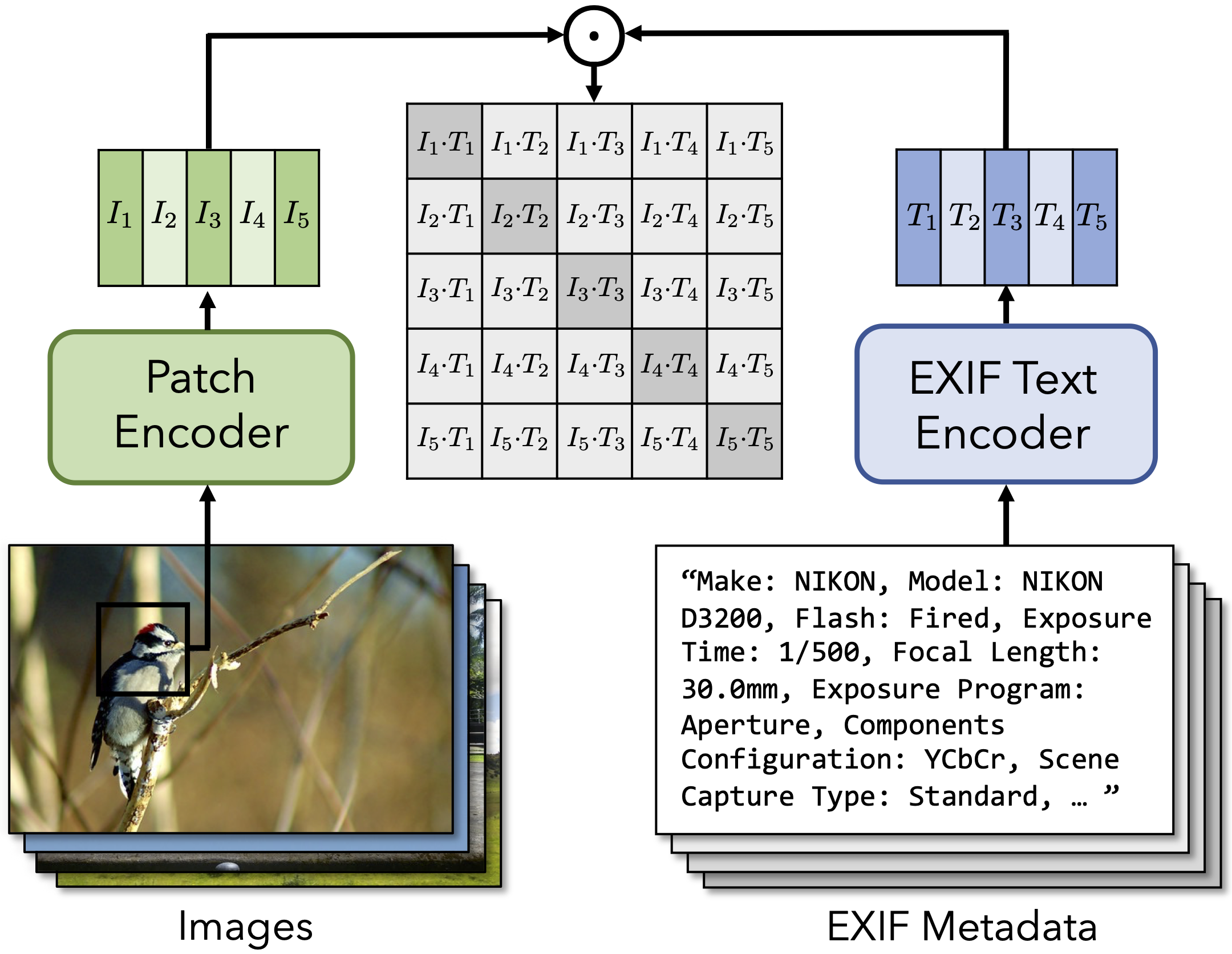 Cross-modal image and photo metadata training
Cross-modal image and photo metadata training
Application: Zero-Shot Splice Detection
We apply our learned representation to tasks that require understanding camera properties. For example, we can
detect image splicing “zero shot” (and without metadata at test time) by finding inconsistent embeddings within an image. We show a
manipulated image that contains content from two source photos. Since these photos were captured with different cameras, the two regions
have dissimilar embeddings (visualized by PCA). We localize the splice by clustering the image’s patch embeddings.
Acknowledgements
This research was developed with funding from the Defense Advanced Research Projects Agency (DARPA) under Contract No. HR001120C0123. The views, opinions and/or findings expressed are those of the author and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.
We thank Alexei Efro, Ziyang Chen, Yuexi Du for the helpful discussions.
The webpage template was adopted from
Colorization project and
HOGgles project.


