We design an iterated learning algorithm that improves the compositionality in large vision-language models, inspired by cultural transmission theory in cognitive science.
We design an iterated learning algorithm that improves the compositionality in large vision-language models, inspired by cultural transmission theory in cognitive science.
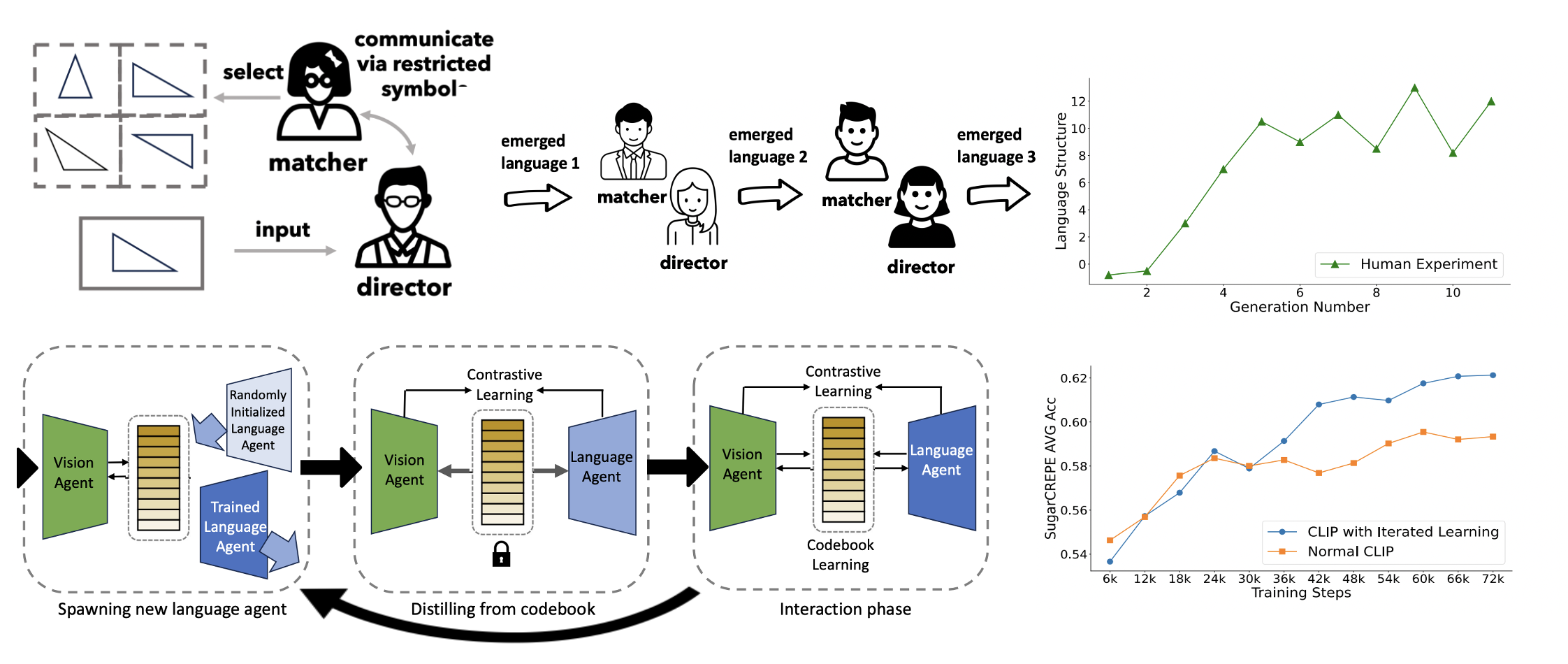
A fundamental characteristic common to both human vision and natural language is their compositional nature. Yet, despite the performance gains contributed by large vision and language pretraining, recent investigations find that most—if not all—our state-of-the-art vision-language models struggle at compositionality. They are unable to distinguish between images of “a girl in white facing a man in black” and “a girl in black facing a man in white”. Moreover, prior work suggests that compositionality doesn't arise with scale: larger model sizes or training data don't help. This paper develops a new iterated training algorithm that incentivizes compositionality. We draw on decades of cognitive science research that identifies cultural transmission—the need to teach a new generation—as a necessary inductive prior that incentivizes humans to develop compositional languages. Specifically, we reframe vision-language contrastive learning as the Lewis Signaling Game between a vision agent and a language agent, and operationalize cultural transmission by iteratively resetting one of the agent's weights during training. After every iteration, this training paradigm induces representations that become “easier to learn”, a property of compositional languages: e.g. our model trained on CC3M and CC12M improves standard CLIP by 4.7%, 4.0% respectfully in the SugarCrepe benchmark.
Why our iterated learning algorithm works? We demonstrate it from both cognitive science point of view and machine learning point of view.
From cognitive science point of view, we demonstrate that iterated learning produces "easy-to-learn" visual representation. we train language encoders from scratch to align with the fixed visual encoder checkpoints (lets the vision agent be a teacher to teach language agent). The language agents achieved significantly higher matching speed when paired with vision representations developed through iterated learning.
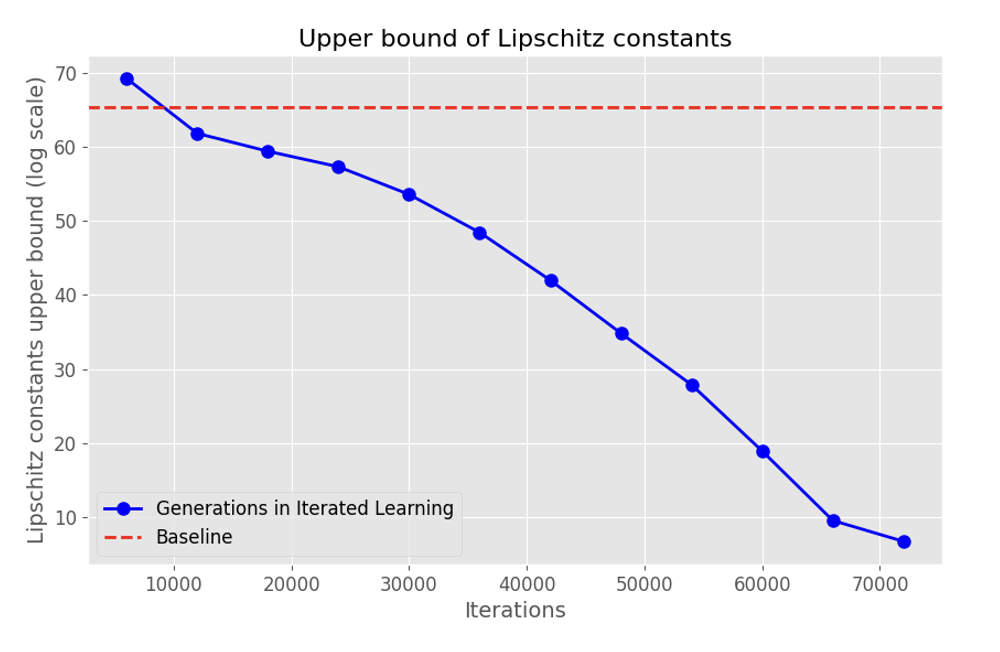
From a machine learning perspective, we find that iterated learning implicitly performs smoothness regularization. As shown in the figure, the estimated upper bound of Lipschitz constant decreases as generation increases in iterated learning setting and is much smaller than the model trained with the standard scheme.
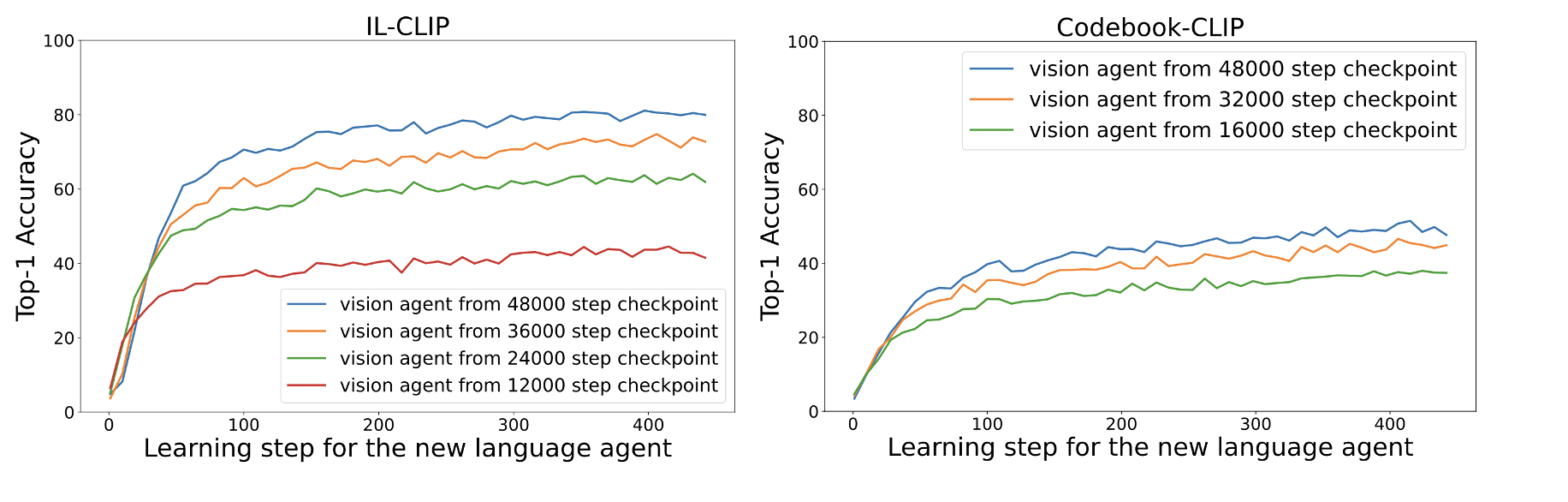
We visualize the learned codebook by retrieving the top 5 most relevant images for each code. We find that the codes correspond to different (somewhat) interpretable semantic concepts. After mapping the codes manually, we reverse the process and interpret which codes are selected when viewing a new image. For example, both the “horse” and “tent” codes are assigned a higher weight when viewing an image that contains both, indicating the model’s compositional understanding.

@inproceedings{zheng2024iterated,
title={Iterated learning improves compositionality in large vision-language models},
author={Zheng, Chenhao and Zhang, Jieyu and Kembhavi, Aniruddha and Krishna, Ranjay},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={13785--13795},
year={2024}
}